Avnac Studio
May 2026
6 min read
Backend Engineer (contract)
Boreas - Job Queue Architecture for Background Removal at Scale
Built a fast, stateless background-removal API that decouples image upload validation from expensive compute work using Redis queues and worker pools, keeping request latency under 200ms regardless of processing time.
<50ms
Upload response
~30s
End-to-end UX
1hr
Result TTL
Built and own this entirely. Open source. Read the code.
At a glance
Problem
Users expected instant upload feedback while background removal took 5-30 seconds per image. Synchronous processing caused timeouts, queue backpressure, OOM crashes, and runaway object storage costs from uncleaned staged files.
Approach
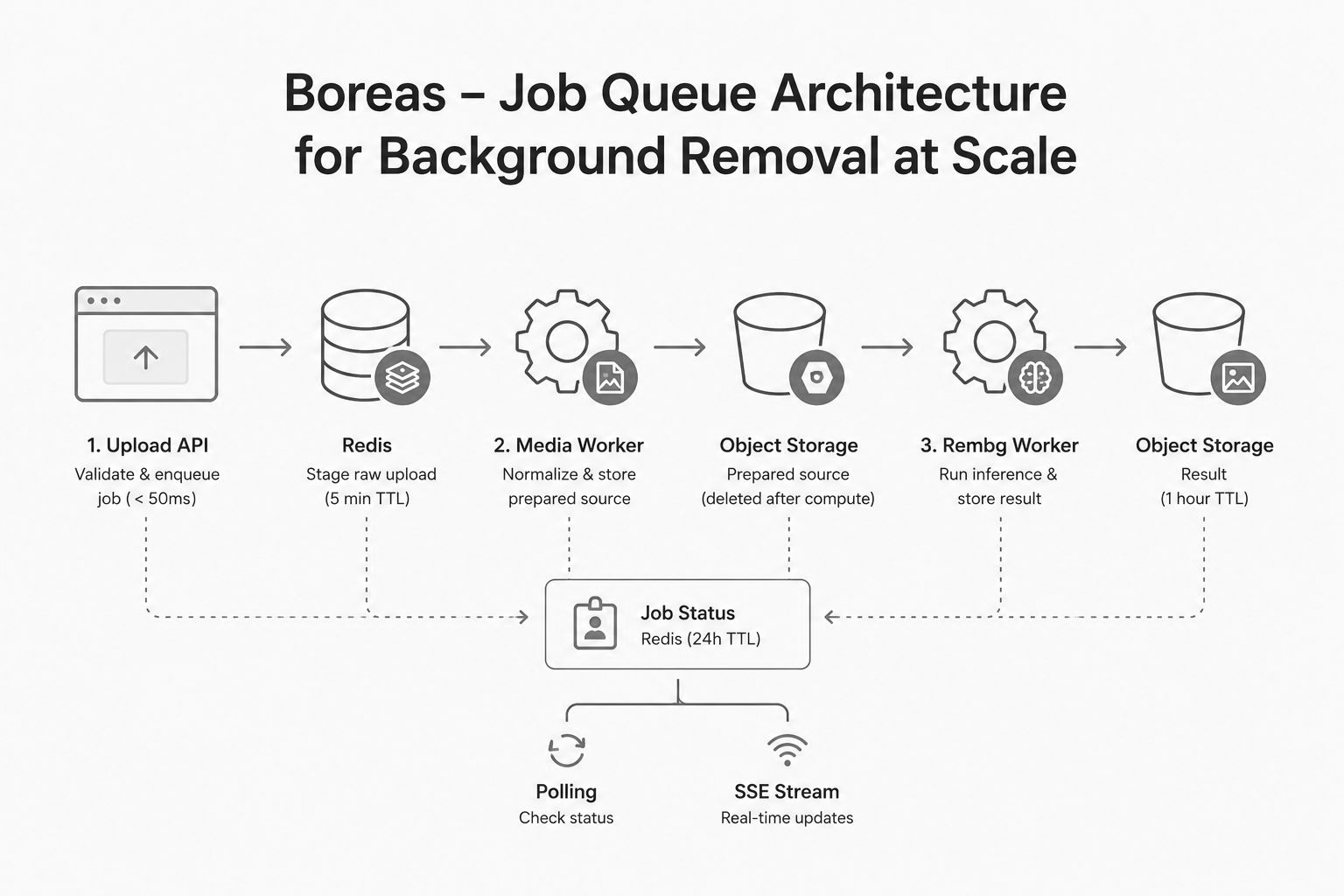
Three-stage pipeline: thin upload handler stages bytes in Redis and returns in under 50ms, media worker normalizes and stores prepared sources, compute worker runs ONNX inference and enforces deterministic object lifecycle with TTLs.
Result
Upload acknowledgment stays under 200ms while inference runs asynchronously. Users get polling or SSE status updates. The system scales from low-cost VPS to higher worker counts through configuration alone.
Write-up
Context
ONNX background removal inference is computationally expensive. Processing a 2MB image takes 5-30 seconds depending on model and hardware. Users expect:
- Fast upload acknowledgment: HTTP request returns within 200ms, not after inference completes.
- Job tracking: Check status via polling or streaming without blocking.
- Abuse protection: Rate limiting to prevent queue saturation.
- Cost visibility: Explicit object lifecycle with deterministic cleanup.
The initial implementation tried processing everything on the request path. Uploads would timeout. Worker processes crashed under queue backpressure. Object storage costs exploded from uncleaned staged files.
Problem
Synchronous request-path processing creates systemic failures:
- Upload + inference on request path leads to 30-second HTTP timeout and user frustration.
- No backpressure mechanism. Slow inference backs up the queue and causes memory exhaustion (OOM).
- Object storage costs skyrocket when uploads are staged but never cleaned.
- Retry logic is ad-hoc. Job state is scattered across Redis, memory, and disk.
- Zero scaling visibility. No insight into queue depth or worker utilization.
- Naive rate limiting applies the same limit to cheap metadata reads and expensive uploads.
Constraints
- Must run on low-cost CPU-only VPS (Hostinger KVM2, 2-4GB RAM).
- ONNX model downloads during cold start can exceed 2 minutes.
- S3-compatible storage charges per API call and per GB stored.
- Horizontal worker scaling requires shared state (Redis).
- User expectation: results within 1 minute, realistically 30 seconds on decent hardware.
Solution: Three-Stage Pipeline
Boreas decomposes the problem into three decoupled stages:
Stage 1: Request Handler - Thin Upload Path
POST /v1/media/jobs
├─ Read upload in bounded chunks (prevent memory spike)
├─ Validate file type (JPEG, PNG, WebP)
├─ Validate file size (< 50MB default)
├─ Store raw bytes to Redis (5-minute TTL)
├─ Create job metadata: { job_id, upload_key, status }
├─ Enqueue ingest worker
└─ Return: { job_id, status: "queued" } in < 50ms
- Entire request path completes in under 50ms.
- Image bytes staged in Redis as temporary handoff buffer.
- No object storage calls on request path.
- Bounded chunk reading prevents OOM.
Stage 2: Media Worker - Normalize and Store Prepared Source
ARQ Media Worker (app/features/media):
1. Dequeue job with upload_key
2. Fetch raw bytes from Redis
3. Validate image headers (prevent corruption)
4. Normalize to configured cap (max 10MB, reduce quality if needed)
5. Upload normalized image to object storage (prepared_source object)
6. Delete raw bytes from Redis (free memory)
7. Update job metadata: prepared_source_url
8. Enqueue rembg compute worker
- Owns input validation and normalization.
- Uploads only the normalized prepared source to storage, not raw upload.
- Clears Redis after successful upload.
- If normalization fails, raw upload naturally expires.
Stage 3: Compute Worker - Background Removal
ARQ Rembg Worker (app/features/rembg):
1. Dequeue job with prepared_source_url
2. Download prepared source from object storage
3. Run rembg ONNX inference
4. Upload final PNG to object storage (result object)
5. Delete prepared source from storage (cleanup)
6. Update job: { status: "done", result_url }
7. Set result TTL: 1 hour via bucket lifecycle rule
- Owns expensive compute only.
- Input is already normalized and bounded.
- Immediately deletes prepared source after inference (cost savings).
- Result URLs expire after 1 hour automatically.
Job State Machine
queued
↓
ingest_queued → ingest_complete
↓
compute_queued → done
↓ ↓
[error] [result expires 1hr]
- Job metadata: Expires from Redis after 24 hours.
- Staged uploads: Expire from Redis after 5 minutes.
- Prepared sources: Deleted immediately after successful inference.
- Results: Expire after 1 hour via bucket lifecycle rule.
- No database needed: Job state is ephemeral by design.
Why Split into Two Workers
Separating input normalization (media worker) from inference (compute worker):
- Request path stays thin. HTTP handler does not touch normalization logic.
- Clear ownership: media prepares safe, bounded input. Rembg owns expensive compute.
- Cleaner retries: if normalization fails, inference never starts. If inference fails, normalization succeeded.
- Cost control: prepared source deleted immediately after inference (no staging period).
- Scaling flexibility: independently tune worker counts (4 media + 8 compute, etc.).
Storage Strategy
Raw Uploads: Redis (5-Minute TTL)
- Temporary handoff buffer between request handler and ingest worker.
- Object storage calls are slower and costlier. Redis is faster for short-lived staging.
- If ingest fails, raw bytes expire naturally. No cleanup logic needed.
Prepared Sources: Object Storage (Deleted After Compute)
- Redis memory is bounded. Prepared sources can be large.
- Object storage is cheaper for intermediate files.
- Ingest worker uploads prepared source, then compute worker downloads and deletes.
- Cost optimization: avoid paying for storage on files that do not reach final result.
Results: Object Storage (1-Hour TTL via Lifecycle Rule)
- Users download results immediately. TTL is intentionally short.
- Bucket lifecycle rule handles automatic deletion.
- Result URLs are presigned, issued to client for direct download.
Explicit object lifecycle:
Raw upload → Redis → 5 min expiry (auto-delete)
Prepared source → Object storage → deleted after compute
Result → Object storage → 1 hour TTL via bucket lifecycle rule
Feature Ownership
Code structure mirrors responsibility:
app/
features/
media/ # Upload API, file validation, ingest worker
rembg/ # Background removal inference, compute worker
health/ # Status and metrics endpoints
core/
bootstrap/ # Startup, dependency initialization
middleware/ # Rate limiting, logging
config/ # Environment configuration
storage/ # S3-compatible client primitives
redis/ # Redis connection pool, ARQ queue registry
- media: owns validation, normalization, prepared source upload.
- rembg: owns background removal inference, result upload, prepared source cleanup.
- health: owns service health checks, queue metrics.
- core: owns infrastructure (bootstrapping, middleware, storage primitives).
This layout makes it immediately obvious where a change belongs and who owns a failure.
Client Patterns
Polling (Cheap)
GET /v1/media/jobs/{job_id}
Return: { status, result_url }
Rate limited: 5 requests/minute per IP
Server-Sent Events (Efficient)
GET /v1/media/jobs/{job_id}/stream
Emit: { status: "ingest_complete" }
Emit: { status: "done", result_url } when ready
Close connection
Polling hits rate limit faster. SSE is the preferred path for real-time updates.
Rate Limiting Strategy
Two separate limits via SlowAPI (Redis-backed moving window):
# Cheap reads, metadata
API_RATE_LIMIT = 5/minute # GET /jobs/{id}
# Expensive operations
UPLOAD_RATE_LIMIT = 5/minute # POST /jobs (upload + ingest)- Per-IP identity: No auth required. IP from request headers.
- Middleware layer: Enforced before routes.
- Conservative limits: Reflect actual resource cost. Uploads and inference are expensive.
Architecture Rationale
| Decision | Rationale |
|---|---|
| Split media + rembg workers | Different responsibilities. Clear ownership. Cleaner retries. |
| Redis for raw uploads | Fast. S3 calls slower/costlier. Temporary handoff buffer (5 min TTL). |
| Ingest normalizes before storage | Bounds file size. Prevents oversized payloads to compute. |
| Delete prepared source after inference | Cost savings. No benefit keeping intermediate files. |
| Result URLs expire after 1 hour | Users download soon. Old results are not kept. |
| Two separate rate limits | Reads are cheap. Uploads are expensive. Different limits reflect cost. |
| Per-IP rate limiting | No auth required. IP is identity. SlowAPI moving-window simpler than fixed-window. |
| Feature ownership in layout | media/, rembg/, health/, core/. Easy to find code. Easy to understand failures. |
| ARQ, not Celery | Lighter library. Workers local to Redis pool. No separate broker process. |
| Keep main.py lean | Real behavior in features or core modules. |
| Explicit JSON + bytes, no pickle | Readable, debuggable, inspectable. Job state is JSON. Upload bytes are raw. |
What Happens Under Load
Scenario: 100 concurrent uploads
- API accepts all 100 in under 100ms total (chunked reads, no buffering).
- All 100 staged in Redis (under 500MB total, depending on content).
- All 100 ingest jobs enqueued.
- Media workers process in parallel:
- 1 worker: serial normalization.
- 4 workers: 4 parallel normalizations.
- Prepared sources uploaded to storage, raw bytes cleared from Redis.
- All 100 jobs move to compute queue.
- Compute workers process in parallel:
- 1 worker: serial inference.
- 8 workers: 8 parallel inferences.
- Results expire after 1 hour. Automatic bucket cleanup.
Request path never blocks. Workers scale independently. Redis is freed before compute starts.
Logging and Observability
Boreas logs at operational inflection points:
- Startup and shutdown
- Request summaries (non-health endpoints)
- Rate limit violations
- Validation failures
- Job enqueue failures
- Ingest completion
- Compute start and completion
- Job failure state transitions
- Degraded health checks
Optional Logfire integration via environment variables for telemetry forwarding. Goal: understand what failed, where, and for which job without noise.
Integration Pattern for Avnac Studio
async function removeBackground(imageFile: File) {
const response = await fetch("https://boreas.api/v1/media/jobs", {
method: "POST",
body: imageFile,
headers: { "Content-Type": "image/png" },
});
const { job_id } = await response.json();
const stream = new EventSource(
`https://boreas.api/v1/media/jobs/${job_id}/stream`,
);
stream.onmessage = async (event) => {
const { status, result_url } = JSON.parse(event.data);
if (status === "done") {
const resultImage = await fetch(result_url);
const blob = await resultImage.blob();
imageCanvas.replaceImage(blob);
stream.close();
}
};
stream.onerror = () => {
stream.close();
showError("Background removal failed. Try a different image.");
};
}From the user perspective: upload, then roughly 500ms for ingest plus ~5s for inference, then the background-removed image appears. All async, no blocking.
Key Takeaway
Decoupling the request path from expensive compute work is not just about performance. It is about correctness. Jobs are first-class entities with explicit state transitions. Object lifecycles are deterministic. Feature ownership is obvious. The system scales from $10/month to $1000/month without code changes, only configuration.
Boreas architecture
Technical appendix
Technical problem
Inference ran on the HTTP request path. No backpressure, ad-hoc retries, job state scattered across Redis and memory, and naive rate limits that treated cheap reads the same as expensive uploads.
Technical approach
Three-stage pipeline: thin upload handler stages bytes in Redis and returns in under 50ms, media worker normalizes and stores prepared sources, compute worker runs ONNX inference and enforces deterministic object lifecycle with TTLs.
Technical outcome
Request path never blocks on inference. Media and rembg workers scale independently. Raw uploads expire in Redis after 5 minutes. Prepared sources delete after compute. Results expire after 1 hour via lifecycle rules.
Related case studies
SMS activation platform
Automated Expiry Detection for Virtual Numbers
Built an automated expiry detection and refund system for temporary virtual numbers using Redis sorted sets when the provider offered no webhook support.
Read case study →Avnac Studio
Saraswati Engine - Extracting a Design Tool from Fabric.js
Avnac Studio's desktop port was blocked by Fabric.js acting as the document model, not just the renderer. We extracted scene logic into a renderer-agnostic engine without pausing the product.
Read case study →